
正文
一场改变游戏规则的合作
4月24日,北京一家酒店会议厅内,深度求索CEO梁文锋按下发布键,DeepSeek V4正式登场。几乎同一时刻,华为昇腾官方确认:昇腾950PR芯片已完成对V4的训练适配,这是国产大模型与国产芯片首次在旗舰级产品上实现深度协同。
这一刻,中国AI产业等了很久。
过去几年,国产大模型飞速发展,但底层算力始终依赖英伟达GPU。从H100到H200,这些性能强大的芯片却像一把悬在头顶的剑——随时可能因为出口管制而断供。黄仁勋曾警告,如果中国无法获得高端芯片,“灾难性后果”将随之而来。
DeepSeek V4与昇腾950PR的联手,用行动给出了回应:不是灾难,而是破局。
参数与性能:不是堆料,是精准
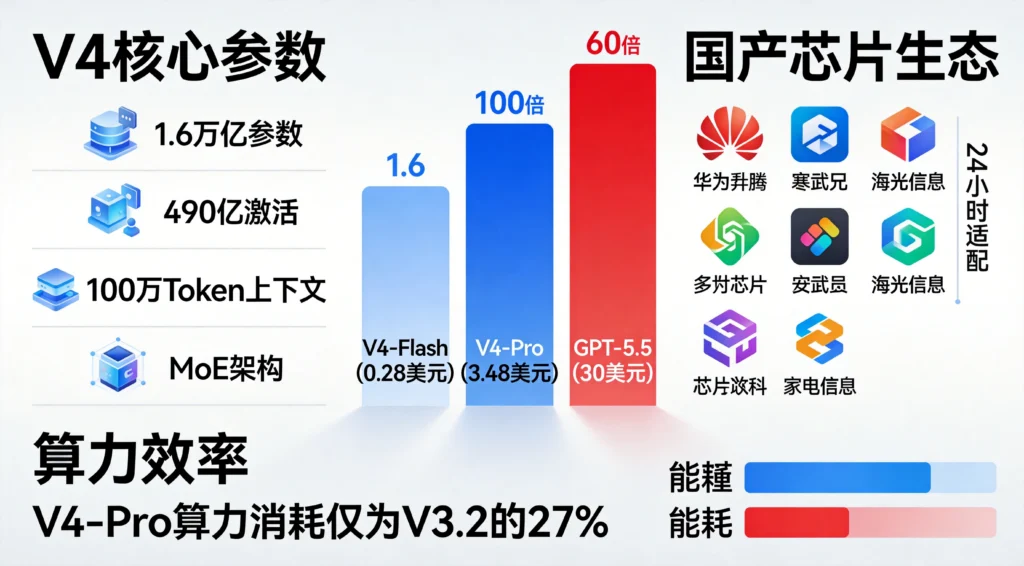
V4系列包含两款产品:旗舰版V4-Pro和轻量版V4-Flash。前者总参数1.6万亿、激活490亿;后者总参数2840亿、激活130亿。两款模型均支持100万Token超长上下文——相当于一次性处理三部《三体》体量的文本。
这些数字背后,是一系列技术创新。
V4引入了压缩稀疏注意力(CSA)和流形约束超连接(mHC)等新技术。在百万Token上下文设置下,V4-Pro每处理一个Token的算力消耗仅为前代V3.2的27%,KV缓存占用仅10%。换句话说,它不仅跑得快,还跑得省。
更重要的是,V4采用混合专家(MoE)架构。与传统大模型每次推理激活全部参数不同,MoE架构让模型在处理不同任务时调用不同的“专家”网络,从而大幅降低计算成本。这解释了为什么V4能以如此亲民的价格提供顶级性能。
价格革命:不到GPT-5.5的六分之一
说到价格,这才是V4真正“炸场”的地方。
V4-Flash的输出定价为每百万Token 2元人民币(约0.28美元),V4-Pro为每百万Token 24元人民币(约3.48美元)。
对比一下GPT-5.5:输出定价每百万Token 30美元(约217元人民币)。
按同口径计算,DeepSeek V4-Flash的价格仅为GPT-5.5的约1/100,V4-Pro约为后者的1/6。
这意味着什么?意味着一家中型企业如果每月需要处理1000万Token的AI任务,使用GPT-5.5每年需要支出约360万美元,而使用V4-Flash仅需约3.6万美元。成本差距高达100倍。
当然,价格差距背后有性能差距。GPT-5.5在多项基准测试中仍保持领先,V4尚未在所有维度实现超越。但正如一位行业观察者所言:“DeepSeek不需要在每个排行榜上夺冠。如果在1/6的成本下能做到’足够接近’,市场就会重新洗牌。”
华为昇腾:从备选到首选
V4的另一个里程碑,是华为昇腾950PR芯片的首发适配。
过去,昇腾芯片的生态成熟度与英伟达存在差距。适配难度大、工具链不完善、性能调优复杂——这些问题让许多开发者望而却步。梁文锋曾在公开场合表示,昇腾“是备选,但开发体验不够好”。
这一次,DeepSeek团队花了大量精力优化适配。梁文锋透露,V4在昇腾上的推理速度“基本追平英伟达GPU”。这意味着国产芯片终于迈过了“好用”这个门槛。
示范效应随即显现。V4发布后24小时内,寒武纪、海光信息、燧原科技等8家国产AI芯片厂商宣布已完成对V4的适配验证。国产大模型与国产算力栈的协同,从单点突破进入规模化阶段。
华为Fellow刘步召表示:“DeepSeek V4证明了国产算力栈已经具备支撑顶级大模型的能力。这是一个重要信号。”
开源策略:基础设施供应商的野心
与OpenAI的闭源路线不同,DeepSeek坚持开源。V4采用对商业友好的MIT协议,权重已在Hugging Face和ModelScope平台开放下载。
这不是梁文锋第一次走开源路线。2025年初,DeepSeek-R1的开源曾在业界引发震动,被认为是“第二个DeepSeek时刻”。那一次,DeepSeek证明了开源模型可以与闭源模型正面竞争;这一次,V4更进一步,证明了开源模型可以在价格上实现碾压式优势。
梁文锋在发布会上解释了DeepSeek的定位:“我们不想做一个什么都做的AI应用公司。我们想做的是智能时代的基础设施供应商——提供最强大的模型底座,让合作伙伴在其上构建各种应用。”
这套逻辑正在被市场接受。阿里、字节跳动、腾讯等大厂已提前下单数十亿规模的昇腾算力,其中相当部分用于部署DeepSeek模型。一位投资人透露:“DeepSeek现在是国内最受欢迎的开源模型,没有之一。”
挑战与隐忧
当然,鲜花与掌声背后,也有一些值得关注的问题。
首先是性能差距。尽管V4在部分指标上逼近GPT-5.5,但在复杂推理、长程对话等场景,差距仍然明显。一位测试过V4的开发者表示:“写代码、处理结构化任务,V4确实很强。但让它做需要深度思考的数学证明,还是能感觉到差距。”
其次是商业化压力。开源模型如何持续盈利,是所有开源大模型公司面临的共同难题。DeepSeek目前的收入主要来自API调用和云服务,但与GPT-5.5的营收规模相比,仍有数量级的差距。梁文锋表示,公司正在探索更多商业模式,包括企业级定制服务、硬件捆绑销售等。
第三是芯片供应链。尽管昇腾950PR已实现对V4的适配,但其产能和稳定性仍需市场验证。在全球AI芯片短缺的背景下,昇腾能否支撑大规模商用部署,还是一个未知数。
写在最后
DeepSeek V4与华为昇腾950PR的联手,不仅仅是两款产品的结合。它代表了一种可能性:当国产大模型与国产算力真正协同起来,中国AI产业就能摆脱对海外供应链的依赖,走出一条独立自主的道路。
这条路不会平坦。性能差距、生态差距、商业化压力——这些挑战不会因为一次发布而消失。
但至少,方向对了。
就像梁文锋在发布会上说的那句话:“我们不需要打败谁。我们只需要证明,这条路走得通。”
发表回复