一、发布背景:AI PC浪潮下的”系统级”争夺战
从ChatGPT引爆大模型浪潮至今,AI助手类产品已经历三个阶段:第一阶段是”问答型”,AI返回文字回答;第二阶段是”插件型”,AI接入工具生态可调用API完成特定任务;第三阶段则是”系统级代理”——AI下沉至操作系统底层,直接感知并操控文件系统、应用程序和系统设置,成为真正”会干活”的数字助手。
这一趋势在2025年末至2026年初集中爆发:微软推出Windows Copilot+PC,苹果在macOS Sequoia中引入系统级Siri,谷歌将Gemini集成至ChromeOS。5月20日,腾讯正式发布Marvis(中文名”马维斯”),官网Marvis.qq.com开放下载,无需邀请码,首批支持Windows、macOS和Android三大平台,iOS版仍在开发中。每位用户每天可使用1000万Token免费额度。
二、技术架构:1+5 Agent体系与安全兜底
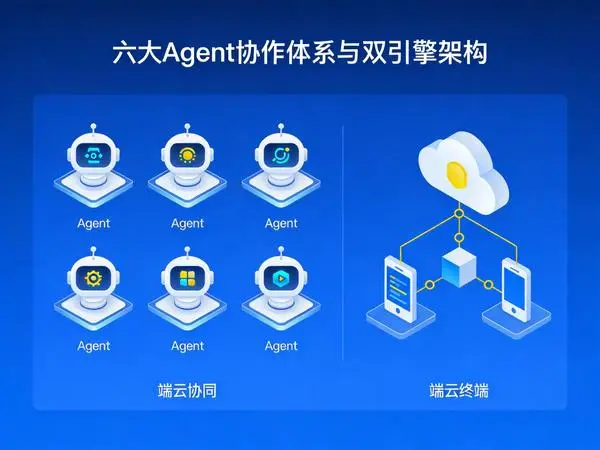
2.1 多Agent协作:主管Agent统领五大专家
马维斯的核心竞争力在于”1个主管Agent + 5个专家Agent”的协作体系。主管Agent理解用户意图、拆解任务、协调调度;五个专家Agent各司其职:
File Agent是区别于传统AI助手最直观的能力——用户不再需要记住文件名,用自然语言描述文件内容或主题,Agent即可通过深度语义理解检索文档、图片乃至PDF文字,并按人像、主题、场景自动整理,构建个人知识库。
Computer Agent直接调用Windows底层API(非模拟键鼠),实现真正的系统级操控:一句话查询硬件配置、电池健康、网络状态;一键优化开机启动项、清理冗余文件、关闭系统广告。这大幅降低了电脑运维门槛。
App Agent通过GUI感知与操作技术”看见”屏幕应用界面并模拟操作。用户说”帮我在同花顺看特斯拉股价”,Agent自动打开应用、定位搜索框、输入股票代码并读取结果,全程无需手动操作。官方表示该能力已支持Windows平台部分Android应用。
Browser Agent接管网页交互,支持自动化数据抓取和网站监控,用户一句话即可设置商品价格追踪或竞品动态监测。
Search Agent整合网络搜索能力,并行调用多个搜索接口,汇总输出结构化答案。
2.2 双引擎架构:效率与隐私的动态平衡
马维斯采用”双引擎”设计,用户可自由切换:
效率模式端云协同——复杂推理由云端处理,文件操作和本地索引尽量在本地完成,调用混元Hunyuan3与DeepSeek V4两款大模型,前者在中文语境更具优势,后者逻辑推理更突出。
隐私模式完全本地推理,采用通义千问端侧模型,文件内容和对话全程不上云、断网可用,专为财务、法务、HR等数据敏感场景设计。
2.3 L2级安全兜底:让AI”干活”不失控制
腾讯为马维斯构建L2级安全机制:普通操作Agent直接执行;敏感操作(删除文件、修改配置)Agent先展示计划获确认后再执行;高敏感操作(支付、账户变更)强制中止交回用户,始终保留人类决策权。
三、应用场景:办公、隐私与跨端协同
日常办公入口:传统”整理发票制表”任务需手动切换邮件、文件夹、Excel,耗时十余分钟;马维斯一句话即可触发File Agent检索附件、Browser Agent抓取邮件、Computer Agent调用Excel完成整理。
隐私敏感场景:隐私模式下,律师审查合同、财务处理未公开财报等场景,首次实现在数据不出本地的同时获得AI辅助能力。
跨端协同:手机可实时查看电脑屏幕并远程操控——下班路上发现重要文件遗留在电脑,无需折返,手机即可远程传输;父母遇到电脑问题,子女可直接跨端协助。
四、竞争格局:腾讯的AI PC战略定位
在全球范围内,马维斯最直接的参照物是微软Windows Copilot+。二者的核心差异体现在:架构深度上,马维斯通过直接调用Windows底层API实现更深度的系统集成,GUI操控和文件语义理解覆盖范围更广;Agent生态上,微软Copilot依赖第三方插件,马维斯的6个预置Agent开箱即用;隐私模式上,Copilot默认云端处理,马维斯完整本地化推理对企业用户合规更友好。
国内赛道中,讯飞星火聚焦语音输入和内容生成,字节豆包移动端有流量优势但缺少桌面系统级能力,百度文心一言和阿里通义均以对话为主。马维斯在”操作系统层级AI助手”这一细分赛道暂无完全对标产品,其核心壁垒来自腾讯社交账号体系和腾讯文档、腾讯会议的生态协同。
五、深度分析:AI助手进化的三重意义
5.1 从”工具”到”代理”:AI价值范式的根本转变
马维斯最深远的影响在于其代表的AI价值范式转变。过去的AI助手本质是”增强版搜索引擎”——AI回答问题,人类执行操作。操作系统级Agent打破了这一局限:人类定义目标,AI拆解步骤并执行执行,人类角色从操作者变为监督者和决策者。这一转变类似从手动挡到自动挡汽车的跨越:驾驶核心逻辑未变,但门槛和效率发生了质变。
5.2 端云协同:AI普惠与隐私合规的平衡之道
马维斯的双引擎架构折射出行业共识——不同类型任务调用不同推理引擎,在效率与安全之间实现动态平衡。随着端侧芯片算力提升和通信协议优化,”数据最小化”与”能力最大化”的双重目标将逐步收敛。
5.3 腾讯AI战略的新支点
马维斯的发布标志着腾讯AI战略从”模型能力”向”产品落地”转型。混元大模型持续迭代、DeepSeek战略投资并行、腾讯云TI平台向企业开放,但在大模型应用端,腾讯此前布局相对分散。马维斯首次将腾讯AI能力以统一、高度产品化形态直接面向终端用户,是腾讯从”模型供应商”向”AI平台运营商”转型的重要一步,并有望成为腾讯AI生态的超级入口。
六、局限与挑战
硬件门槛:Windows端需至少6核CPU、16GB内存;Mac端需M1及以上芯片。部分老旧设备用户暂时无法完整体验。
跨端稳定性:当前版本跨端操控存在一定延迟,弱网环境下仍有优化空间,部分第三方应用GUI感知偶有失效。
非腾讯生态适配:马维斯深度集成腾讯系应用生态,对非腾讯系应用支持仍在扩展中。
七、展望:AI PC的下一程
马维斯指向三条技术演进主线:一是感知能力拓展,从屏幕视觉和文件理解向声音、摄像头、IoT设备感知延伸;二是执行能力深化,从软件操作向软硬件协同演进;三是记忆与个性化,AI Agent从每次清零进化为持续理解用户习惯、提供主动服务。
市场竞争层面,预计百度、字节、阿里等互联网巨头将加速跟进,华为、小米等硬件厂商可能结合自有PC产品推出深度定制版本。AI PC操作系统竞争格局将在2026年下半年至2027年迎来真正爆发。
对于普通用户,一个全新的计算范式正在到来:人与电脑的交互正从学习软件操作转变为用自然语言指挥AI完成任务。电脑不再是需要学习的工具,而真正成为可对话、可信任、可托付的智能伙伴。马维斯或许只是这个时代的序章,但它所描绘的未来图景,已不再遥远。
【正文完】
本文综合自科技日报、环球网、新民晚报、CSDN等媒体报道,参考腾讯官方发布信息。